
TCMalloc
thread-caching malloc
顾名思义,这个malloc算法是与thread有关的,直观理解上,就是每个thread单独维护一个内存池,这样,各个thread之间的malloc操作就不会相互造成锁的竞争了
不同的malloc算法,就是不同的内存池算法,一是为了减少从os申请内存的次数,二也要增加分配给用户的速度
但是注意,os本身其实也有不同的内存分配算法
Prerequisite
要了解比较高阶的tcmalloc,我们首先要知道传统的内存分配算法,比如伙伴关系,slab,隐式free-list,显式free-list等(slab应该也是一种free-list),基于bitmap的等等
可以看看这个回答, 这个答主给出了从简单到复杂的内存池设计
TCMalloc
实际上,官网的文档已经讲的相对很清楚了: tcmalloc
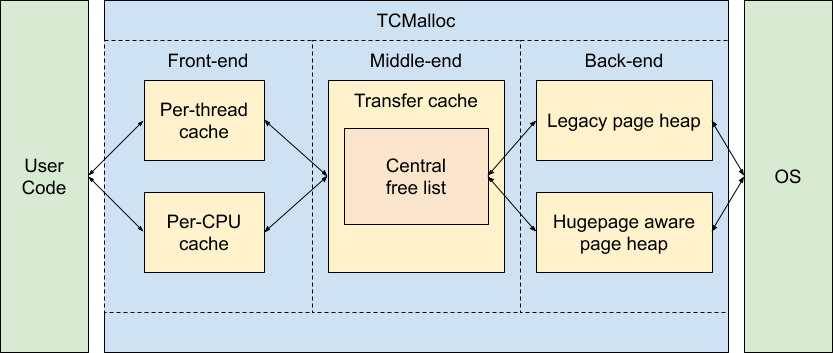
实现细节
重命名
#define TCMALLOC_ALIAS(tc_fn) \
__attribute__((alias(#tc_fn), visibility("default")))
extern "C" {
void* malloc(size_t size) noexcept TCMALLOC_ALIAS(TCMallocInternalMalloc);
void free(void* ptr) noexcept TCMALLOC_ALIAS(TCMallocInternalFree);
}
alias可用于完成的函数调用的重命名,此时,调用malloc,将会重定向到TCMallocInternalMalloc
但是__attribute__((alias(...)))是gcc的拓展,对于其他编译器,最差的情况也不过是覆盖掉这个weak symbol而已(也就是重定义redefine)
只有弱符号才可被覆盖,如果是强符号(一般的函数名),则会panic报错函数重定义
extern "C" {
void* malloc(size_t s) noexcept { return TCMallocInternalMalloc(s); }
void free(void* p) noexcept { TCMallocInternalFree(p); }
}
对于不同的libc,有不同的实现,甚至对不同的编译器,操作系统都有不同的实现:
// Every libc has its own way of doing this, and sometimes the compiler
// matters too, so we have a different file for each libc, and often
// for different compilers and OS’s.
我们常用的是glibc+gcc,也就是都属于gnu
TCMallocInternalMalloc
extern "C" ABSL_CACHELINE_ALIGNED void* TCMallocInternalMalloc(
size_t size) noexcept {
// Use TCMallocInternalMemalign to avoid requiring size %
// alignof(std::max_align_t) == 0. TCMallocInternalAlignedAlloc enforces this
// property.
return TCMallocInternalMemalign(alignof(std::max_align_t), size);
}
extern "C" void* TCMallocInternalMemalign(size_t align, size_t size) noexcept {
ASSERT(absl::has_single_bit(align));
return fast_alloc(MallocPolicy().AlignAs(align), size);
}
fast_alloc
template <typename Policy, typename CapacityPtr = std::nullptr_t>
static inline void* ABSL_ATTRIBUTE_ALWAYS_INLINE
fast_alloc(Policy policy, size_t size, CapacityPtr capacity = nullptr) {
// If size is larger than kMaxSize, it's not fast-path anymore. In
// such case, GetSizeClass will return false, and we'll delegate to the slow
// path. If malloc is not yet initialized, we may end up with cl == 0
// (regardless of size), but in this case should also delegate to the slow
// path by the fast path check further down.
uint32_t cl;
bool is_small =
Static::sizemap().GetSizeClass(size, policy.align(),
&cl);
if (ABSL_PREDICT_FALSE(!is_small)) {
return slow_alloc(policy, size, capacity);
}
// When using per-thread caches, we have to check for the presence of the
// cache for this thread before we try to sample, as slow_alloc will
// also try to sample the allocation.
#ifdef TCMALLOC_DEPRECATED_PERTHREAD
ThreadCache* const cache = ThreadCache::GetCacheIfPresent();
if (ABSL_PREDICT_FALSE(cache == nullptr)) {
return slow_alloc(policy, size, capacity);
}
#endif
// TryRecordAllocationFast() returns true if no extra logic is required, e.g.:
// - this allocation does not need to be sampled
// - no new/delete hooks need to be invoked
// - no need to initialize thread globals, data or caches.
// The method updates 'bytes until next sample' thread sampler counters.
if (ABSL_PREDICT_FALSE(!GetThreadSampler()->TryRecordAllocationFast(size))) {
return slow_alloc(policy, size, capacity);
}
// Fast path implementation for allocating small size memory.
// This code should only be reached if all of the below conditions are met:
// - the size does not exceed the maximum size (size class > 0)
// - cpu / thread cache data has been initialized.
// - the allocation is not subject to sampling / gwp-asan.
// - no new/delete hook is installed and required to be called.
ASSERT(cl != 0);
void* ret;
#ifndef TCMALLOC_DEPRECATED_PERTHREAD
// The CPU cache should be ready.
ret = Static::cpu_cache().Allocate<Policy::handle_oom>(cl);
#else // !defined(TCMALLOC_DEPRECATED_PERTHREAD)
// The ThreadCache should be ready.
ASSERT(cache != nullptr);
ret = cache->Allocate<Policy::handle_oom>(cl);
#endif // TCMALLOC_DEPRECATED_PERTHREAD
if (!Policy::can_return_nullptr()) {
ASSUME(ret != nullptr);
}
SetClassCapacity(ret, cl, capacity);
return ret;
}
略复杂,没看懂
Slab
class TcmallocSlab {
public:
struct Slabs {
std::atomic<int64_t> header[NumClasses];
void* mem[((1ul << Shift) - sizeof(header)) / sizeof(void*)];
};
private:
struct Header {
// All values are word offsets from per-CPU region start.
// The array is [begin, end).
uint16_t current;
// Copy of end. Updated by Shrink/Grow, but is not overwritten by Drain.
uint16_t end_copy;
// Lock updates only begin and end with a 32-bit write.
uint16_t begin;
uint16_t end;
// Lock is used by Drain to stop concurrent mutations of the Header.
// Lock sets begin to 0xffff and end to 0, which makes Push and Pop fail
// regardless of current value.
bool IsLocked() const;
void Lock();
};
Slabs* slabs_ = nullptr;
}
算了,折磨人